> ## Documentation Index
> Fetch the complete documentation index at: https://docs.cloudthinker.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Kubernetes 상태 모니터링
> Kai를 사용하여 EKS 클러스터 상태를 모니터링하고, 리소스 낭비를 발견하며, 문제가 프로덕션에 영향을 미치기 전에 HPA 권고안을 받으세요.
Kai는 Amazon EKS 클러스터를 지속적으로 모니터링하여, 과도하게 프로비저닝된 파드, 활용률이 낮은 노드, 장애를 일으키기 전에 누락된 오토스케일링 정책을 발견합니다.
## 시나리오
플랫폼 팀이 여러 네임스페이스에 걸쳐 프로덕션 EKS 클러스터를 운영하고 있습니다. CPU 알림은 간헐적으로 발생하지만 조사는 느립니다 — 엔지니어들이 수백 개의 파드에 걸쳐 로그, 메트릭, 이벤트를 상관 분석하기 위해 수동으로 `kubectl` 명령을 실행합니다.
수동 Kubernetes 트러블슈팅의 어려움
팀은 Kai에게 클러스터를 엔드투엔드로 평가하고, 리소스 낭비를 파악하며, 오토스케일링 정책이 없는 곳에 권고안을 제시해 달라고 요청합니다.
## 단계별 안내
### Kai를 클러스터에 연결
[Kubernetes 연결 가이드](/ko/guide/connections/kubernetes)를 따라 Kai가 EKS 클러스터에 접근할 수 있도록 하세요. 연결이 **Connected** 상태를 표시하면 Kai가 클러스터를 직접 쿼리할 수 있습니다.
### 파드 리소스 활용률 분석
```text theme={null}
@kai #report analyze pod resource utilization in production namespace
```
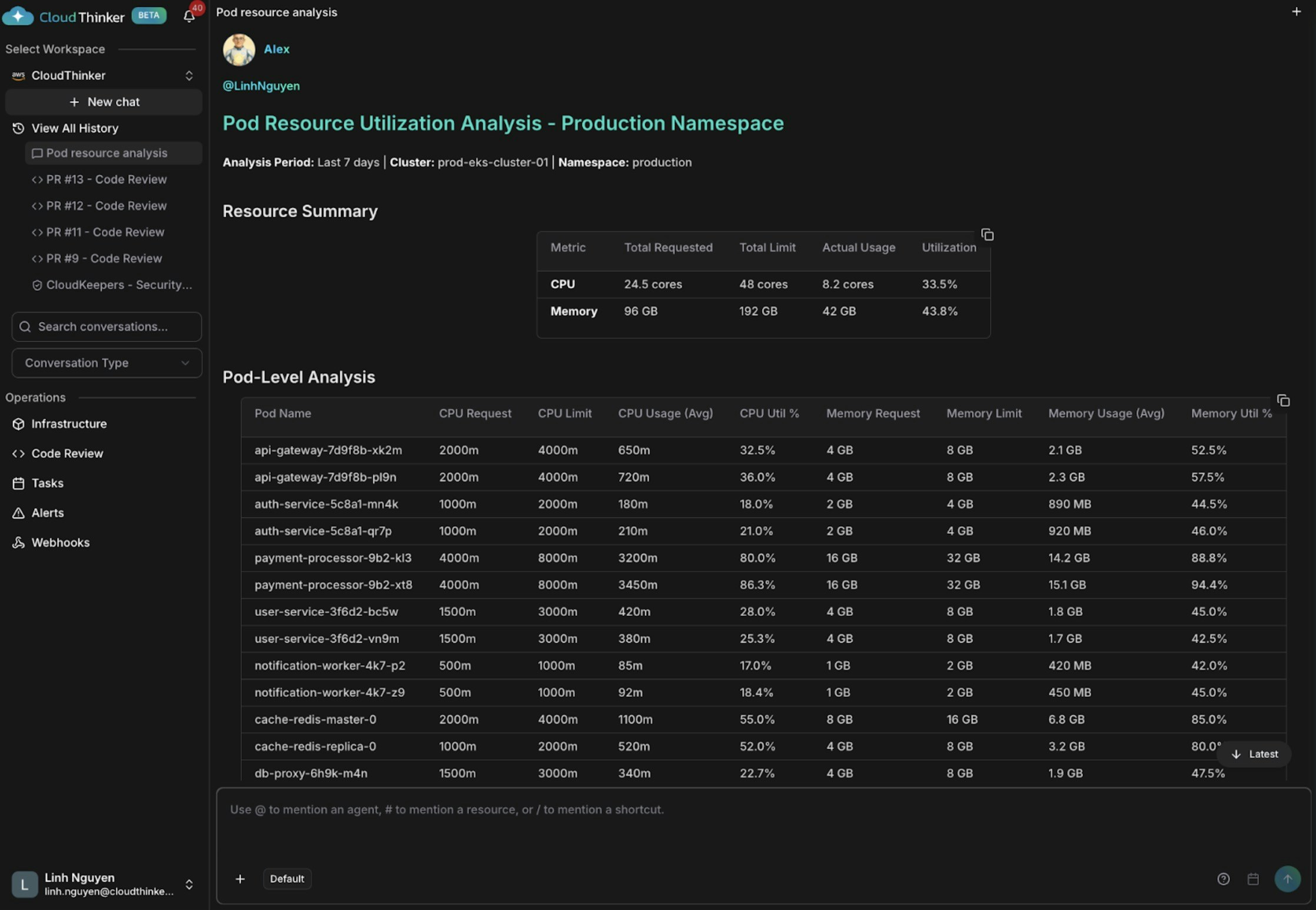
파드 리소스 활용률 분석
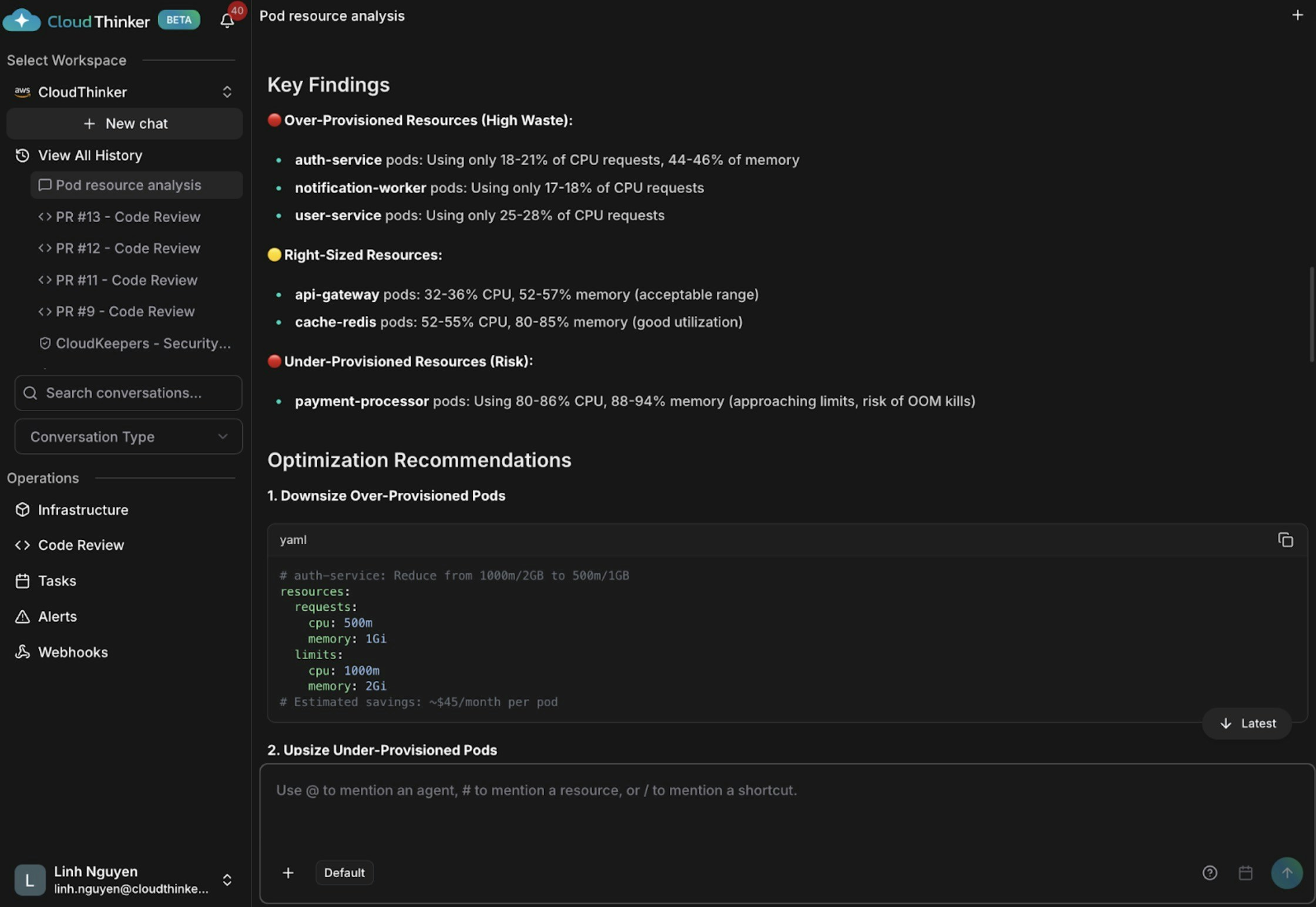
성능 권고안이 포함된 파드 분석 시각화
Kai가 세 가지 발견 사항을 표시합니다: auth-service와 notification-worker는 과도하게 프로비저닝되어 있고(CPU 18–21%), api-gateway와 cache-redis는 적절한 크기이며, payment-processor는 CPU 80–86%와 메모리 88–94%로 위험할 정도로 프로비저닝이 부족하여 OOM 킬 및 서비스 중단 위험이 높습니다.
### 활용률이 낮은 노드 파악
```text theme={null}
@kai #chart identify nodes with <30% CPU utilization
```
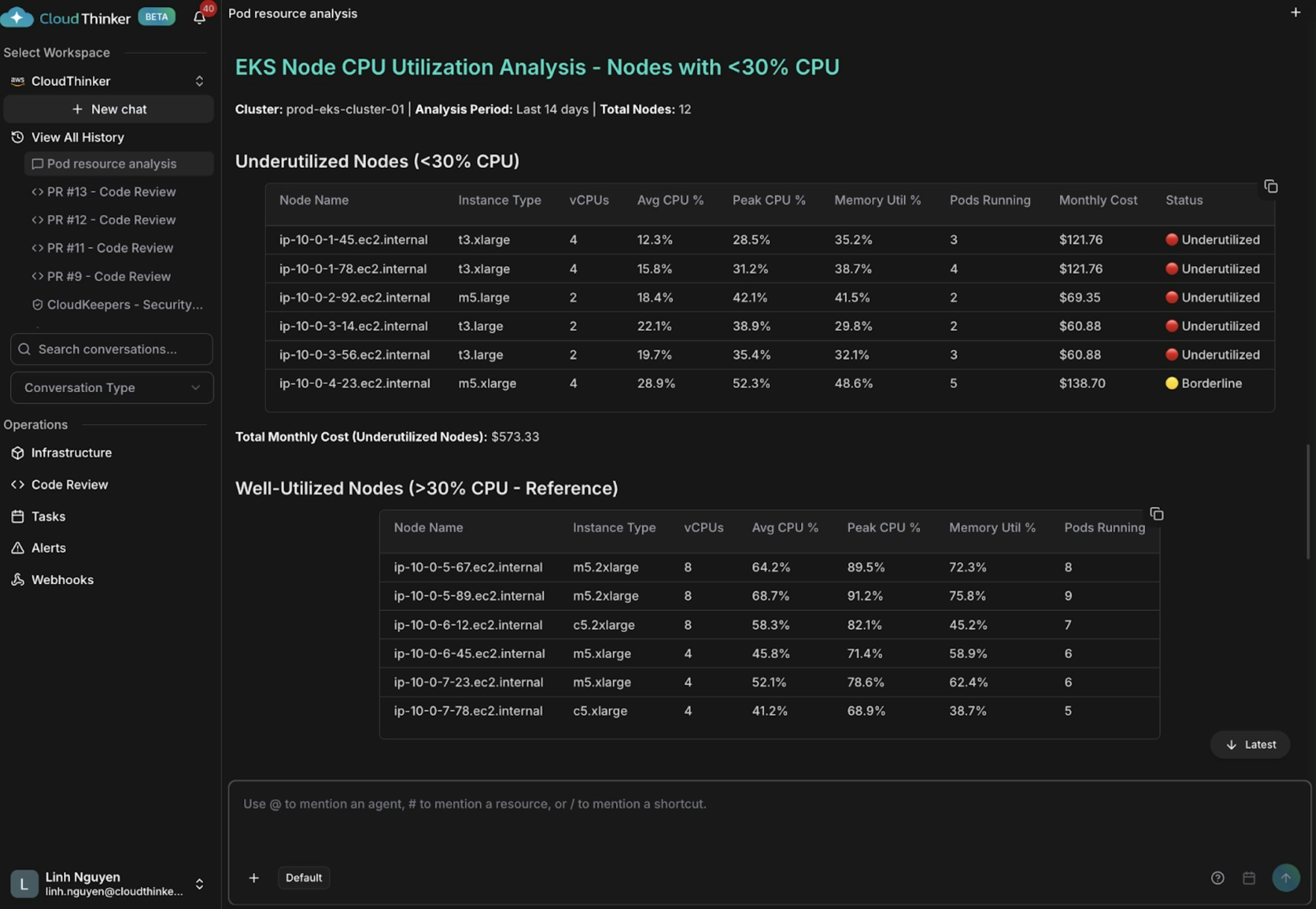
활용률이 낮은 인스턴스를 보여주는 노드 CPU 활용률 분석
Kai가 평균 CPU 30% 미만(일부는 12–15%에 불과)인 노드 다섯 개를 발견하여 월 약 \$573를 낭비하고 있음을 확인합니다. 경량 워크로드를 실행하는 과도하게 큰 t3.xlarge 인스턴스와 — 불량한 파드 스케줄링으로 인해 — 일부 노드에는 2–3개의 파드만 있는 반면 다른 노드에는 8–9개가 있습니다.
### HPA 권고안 받기
```text theme={null}
@kai #recommend HPA policies for web deployments
```
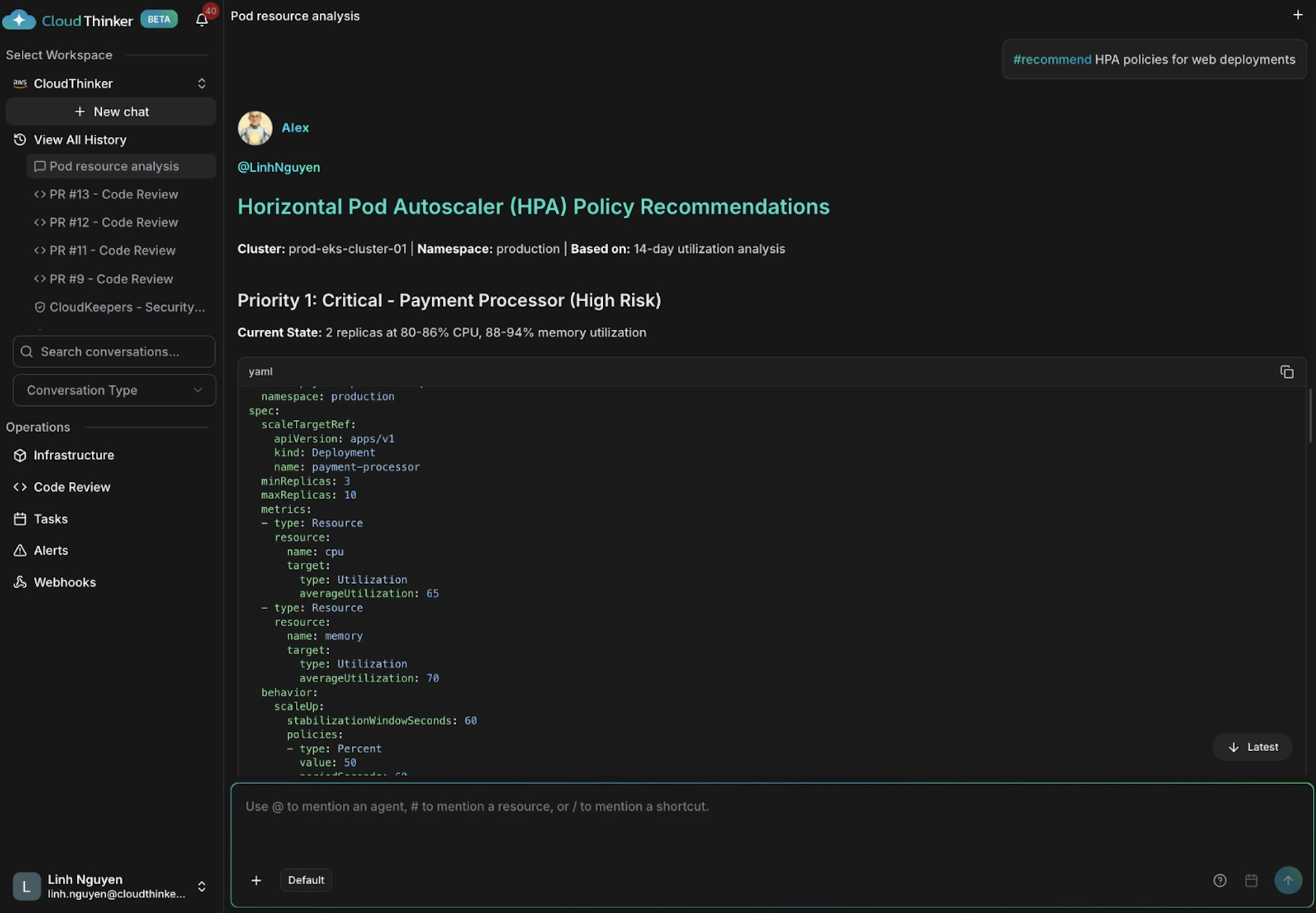
오토스케일링을 위한 HPA 정책 권고안
Kai가 payment-processor를 심각한 위험으로 표시합니다 — 복제본 2개에서 CPU 80–86%, 오토스케일링 없음. api-gateway에 트래픽 급증을 처리하기 위한 HPA 추가를 권고하고, user-service와 auth-service에서 과잉 용량을 제거할 것을 권고합니다.
## 효과적인 이유
* \*\*[Kai](/ko/guide/agents/kai)\*\*가 클러스터 API를 직접 쿼리하여 수동 `kubectl` 세션과 도구 전환을 대체합니다.
* **크로스 레이어 상관 분석**이 파드 활용률, 노드 용량, 스케줄링 패턴을 단일 분석 과정에서 연결합니다.
* \*\*[`#report`](/ko/guide/language)와 [`#chart`](/ko/guide/language)\*\*가 Kai가 발견 사항을 표시하기 전에 추론할 수 있는 구조화된 출력을 생성합니다.
* \*\*[`#recommend`](/ko/guide/language)\*\*가 원시 메트릭 덤프 대신 실행 가능한 HPA 정책 변경 사항을 생성합니다.
* \*\*[CloudKeepers](/ko/guide/infrastructure/cloudkeepers)\*\*가 이 분석을 스케줄에 따라 실행하여 온콜 엔지니어가 호출받기 전에 발견 사항이 전달됩니다.
## 직접 시도해 보기
Kubernetes 엔지니어 에이전트 Kai의 전체 기능
CloudThinker를 EKS 클러스터에 연결하는 단계별 가이드
Kubernetes 서비스 의존성을 매핑하여 인시던트 근본 원인 분석을 빠르게
Kubernetes 워크로드 전반에 걸쳐 지속적인 상태 검사를 자동으로 실행