Tình huống
Một nhóm platform đang vận hành cụm EKS production trải dài nhiều namespace. Cảnh báo CPU xuất hiện ngắt quãng nhưng điều tra chậm chạp — kỹ sư phải chạy thủ công các lệnhkubectl qua hàng trăm pod để tương quan log, metrics, và event.
Thách thức khi xử lý sự cố Kubernetes thủ công
Nhóm yêu cầu Kai đánh giá toàn diện cụm, xác định lãng phí tài nguyên, và khuyến nghị chính sách autoscaling cho những nơi còn thiếu.Hướng dẫn từng bước
Làm theo hướng dẫn kết nối Kubernetes để cấp cho Kai quyền truy cập cụm EKS của bạn. Khi kết nối hiển thị trạng thái Connected, Kai có thể truy vấn cụm trực tiếp.
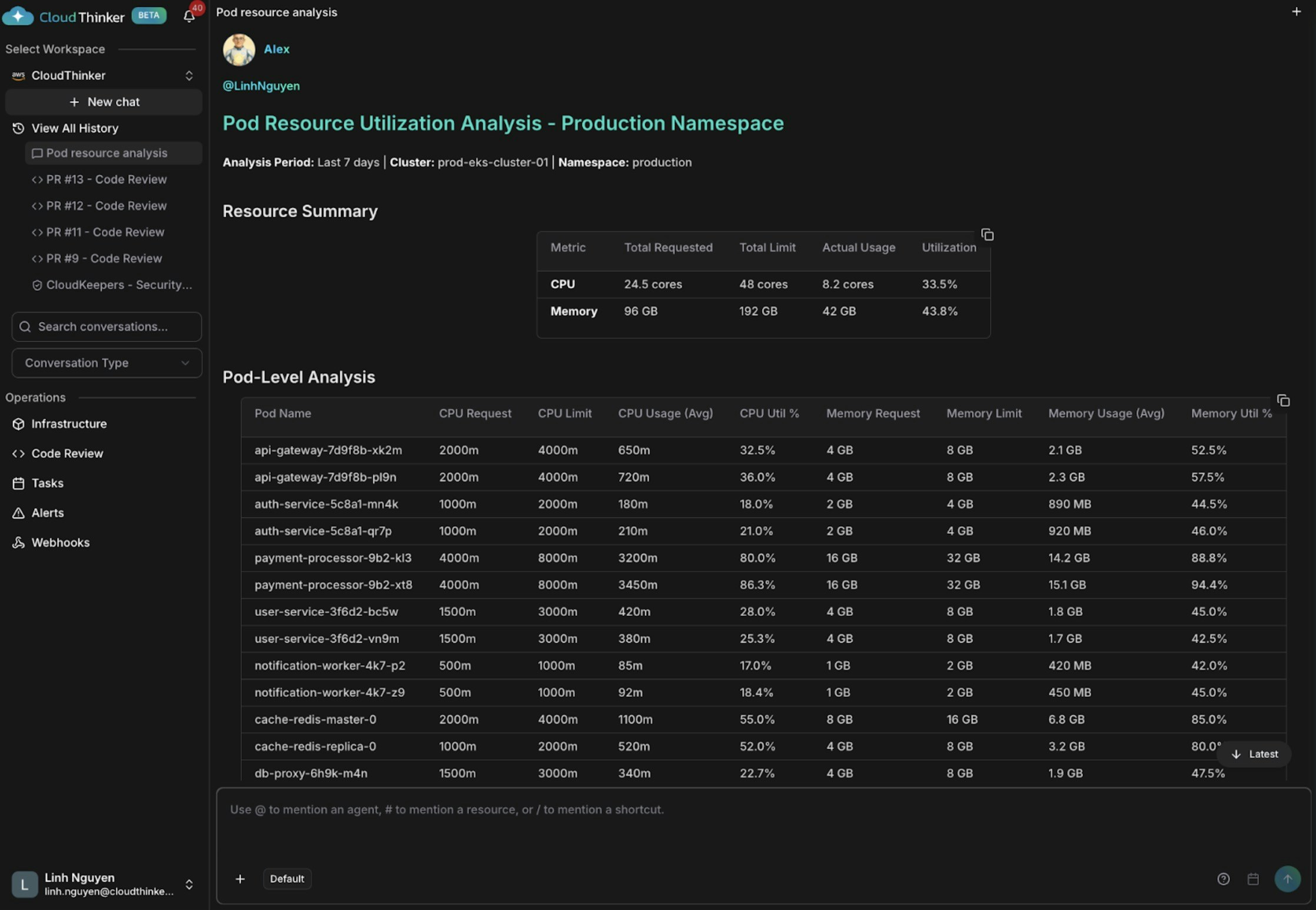
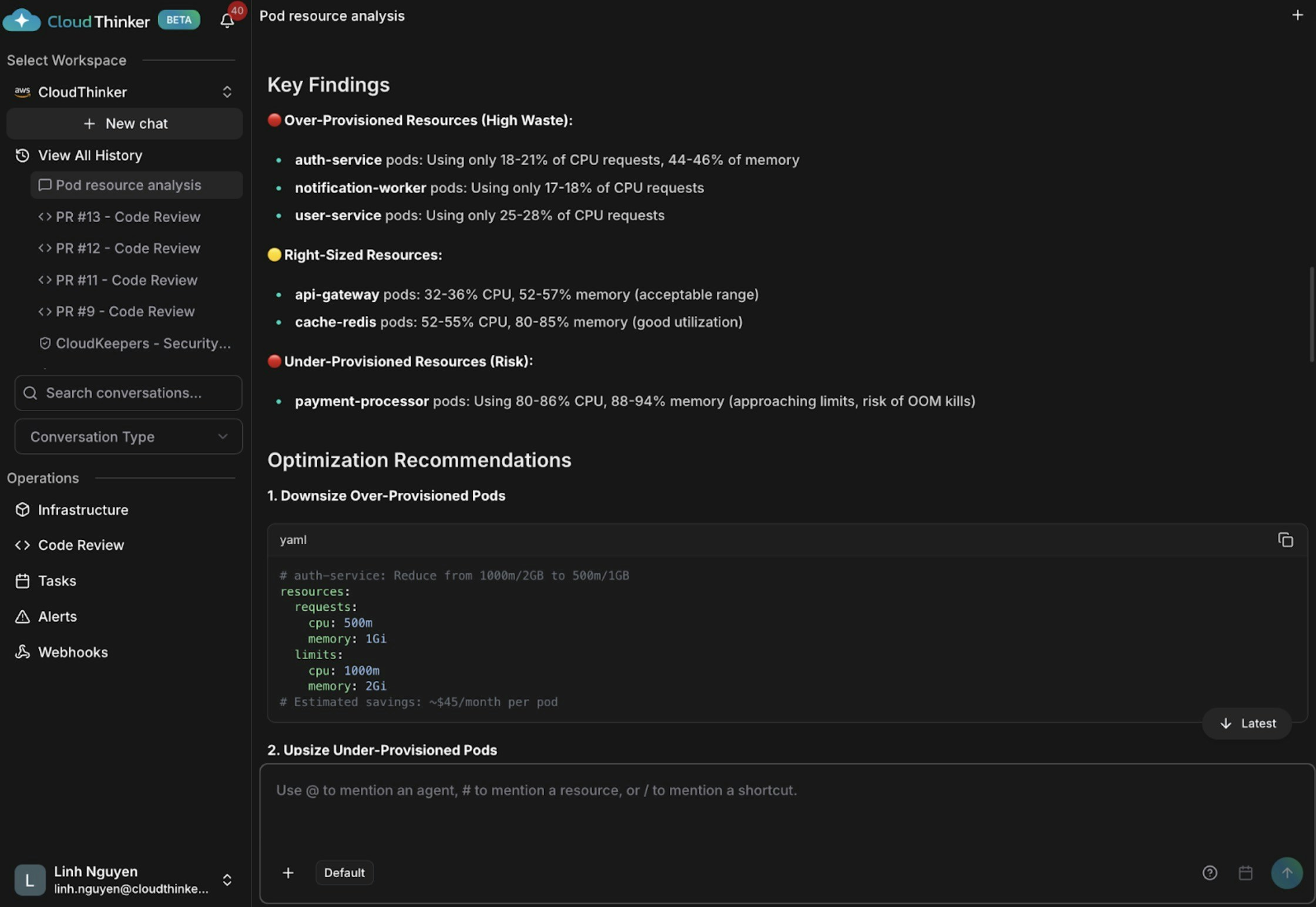
Kai phát hiện ba vấn đề: auth-service và notification-worker được cấp phát thừa (CPU 18–21%), api-gateway và cache-redis có kích thước phù hợp, và payment-processor đang thiếu tài nguyên nguy hiểm ở mức CPU 80–86% và bộ nhớ 88–94% — có nguy cơ cao bị OOM kill và gián đoạn dịch vụ.
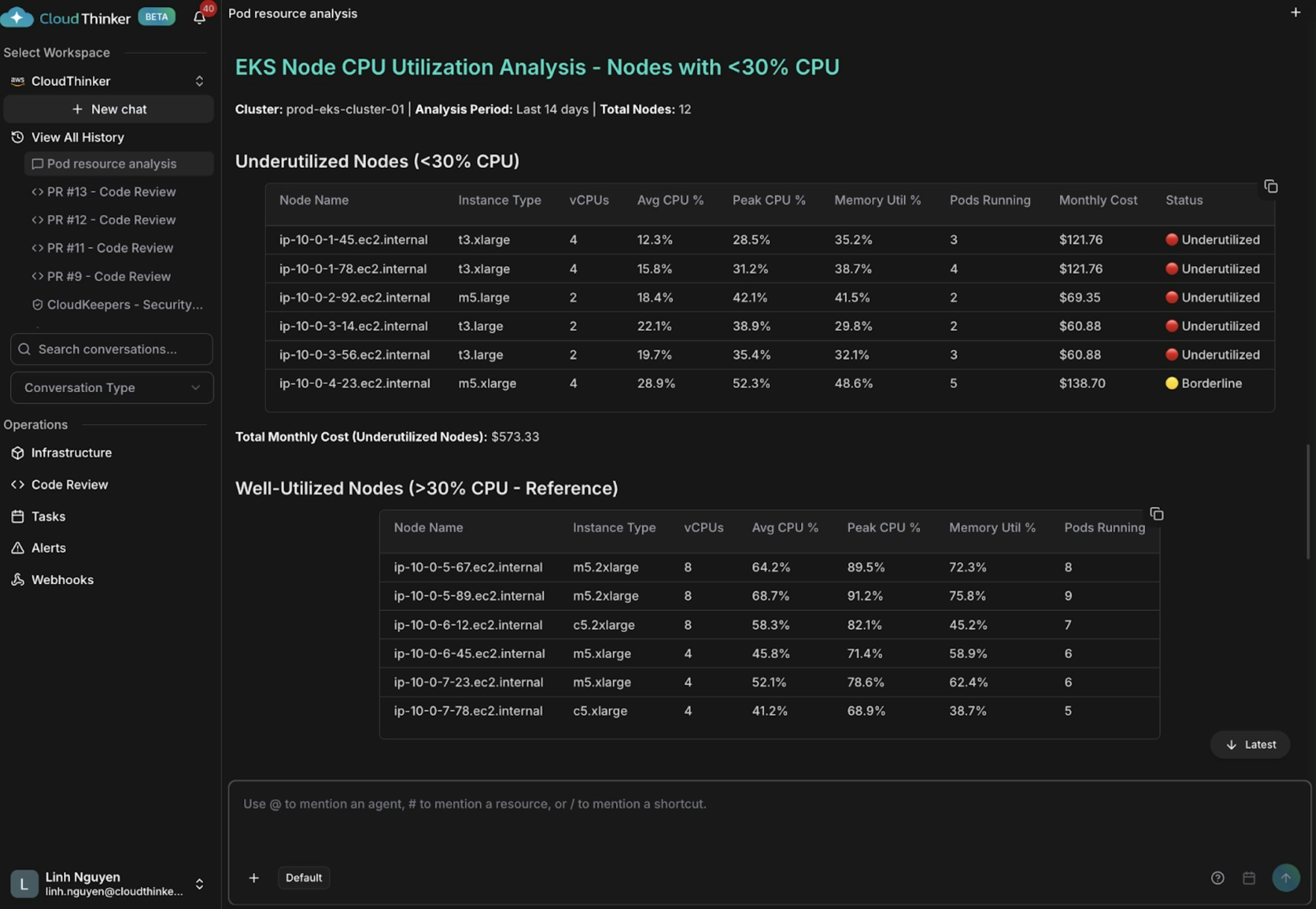
Kai tìm thấy năm node có mức CPU trung bình dưới 30% (một số chỉ 12–15%), lãng phí khoảng $573 mỗi tháng. Các instance t3.xlarge quá lớn chạy workload nhẹ — kết hợp với lịch trình pod kém — khiến một số node chỉ có 2–3 pod trong khi các node khác mang 8–9 pod.
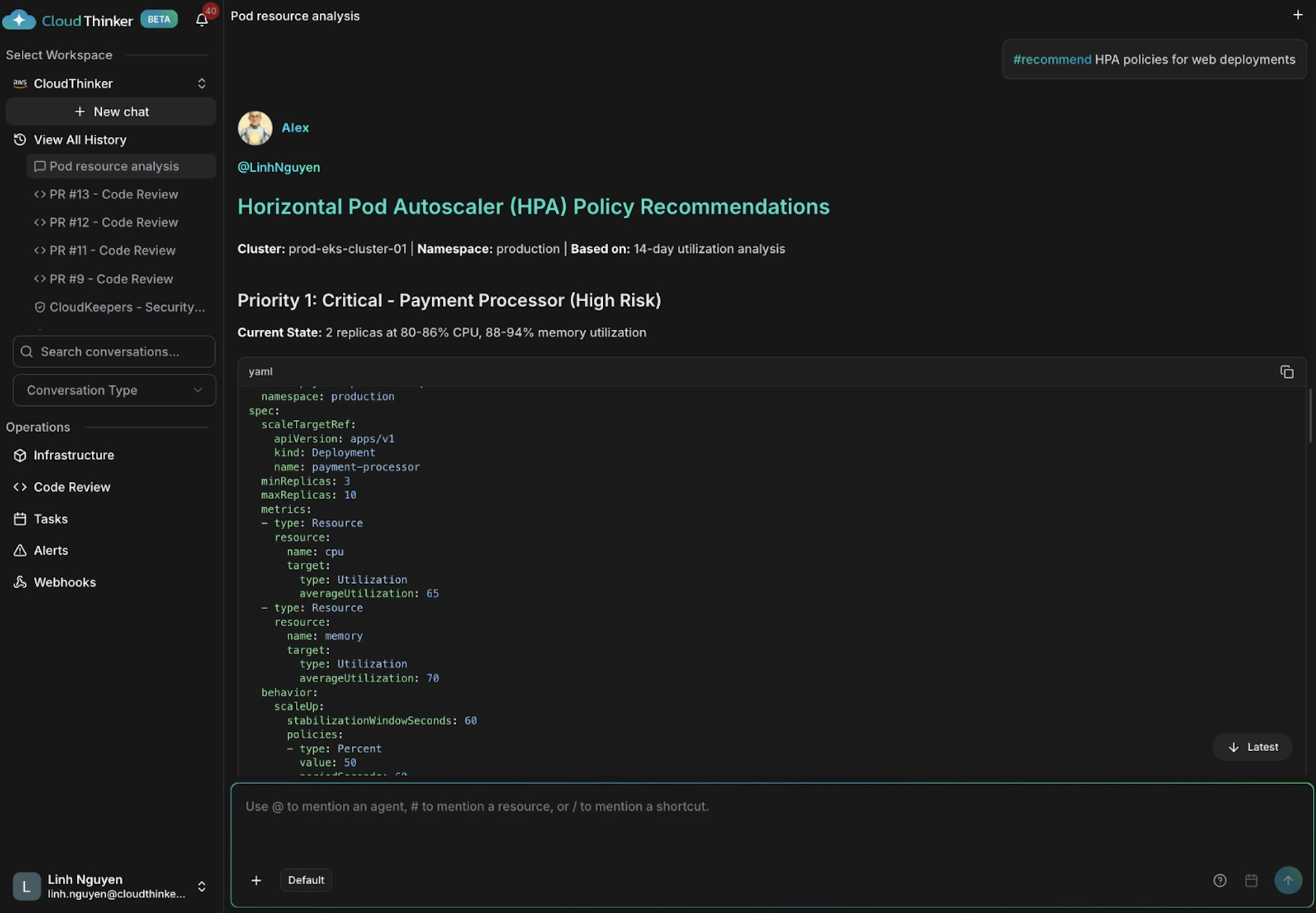
Điều gì tạo nên hiệu quả
- Kai truy vấn trực tiếp cluster API, thay thế các phiên
kubectlthủ công và chuyển đổi công cụ. - Tương quan đa lớp liên kết mức sử dụng pod, dung lượng node, và mẫu lịch trình trong một lượt phân tích duy nhất.
#reportvà#charttạo đầu ra có cấu trúc để Kai suy luận trước khi trình bày phát hiện.#recommendtạo ra các thay đổi chính sách HPA có thể thực thi thay vì chỉ dump metrics thô.- CloudKeepers có thể chạy phân tích này theo lịch để phát hiện vấn đề trước khi kỹ sư trực bị gọi.
Tự mình thử
Tài liệu tham khảo agent Kai
Toàn bộ khả năng của Kai, agent Kỹ sư Kubernetes
Kết nối Kubernetes
Hướng dẫn từng bước kết nối CloudThinker với cụm EKS của bạn
Topology Explorer
Vẽ sơ đồ phụ thuộc dịch vụ Kubernetes để phân tích nguyên nhân gốc rễ nhanh hơn
CloudKeepers
Chạy kiểm tra sức khỏe liên tục trên workload Kubernetes của bạn một cách tự động