シナリオ
あるプラットフォームチームが複数のネームスペースにまたがる本番EKSクラスターを運用しています。CPUアラートは断続的に発生していますが、調査は遅い——エンジニアが何百ものポッドに対して手動でkubectl コマンドを実行し、ログ・メトリクス・イベントを相関させる必要があるからです。
Kubernetesの手動トラブルシューティングの課題
チームはKai にクラスター全体のエンドツーエンドの評価、リソースの無駄の特定、オートスケーリングポリシーが欠けている箇所への推奨を依頼します。ウォークスルー
Kubernetes接続ガイドに従い、Kai にEKSクラスターへのアクセス権を付与します。接続がConnectedと表示されたら、Kai はクラスターを直接クエリできます。
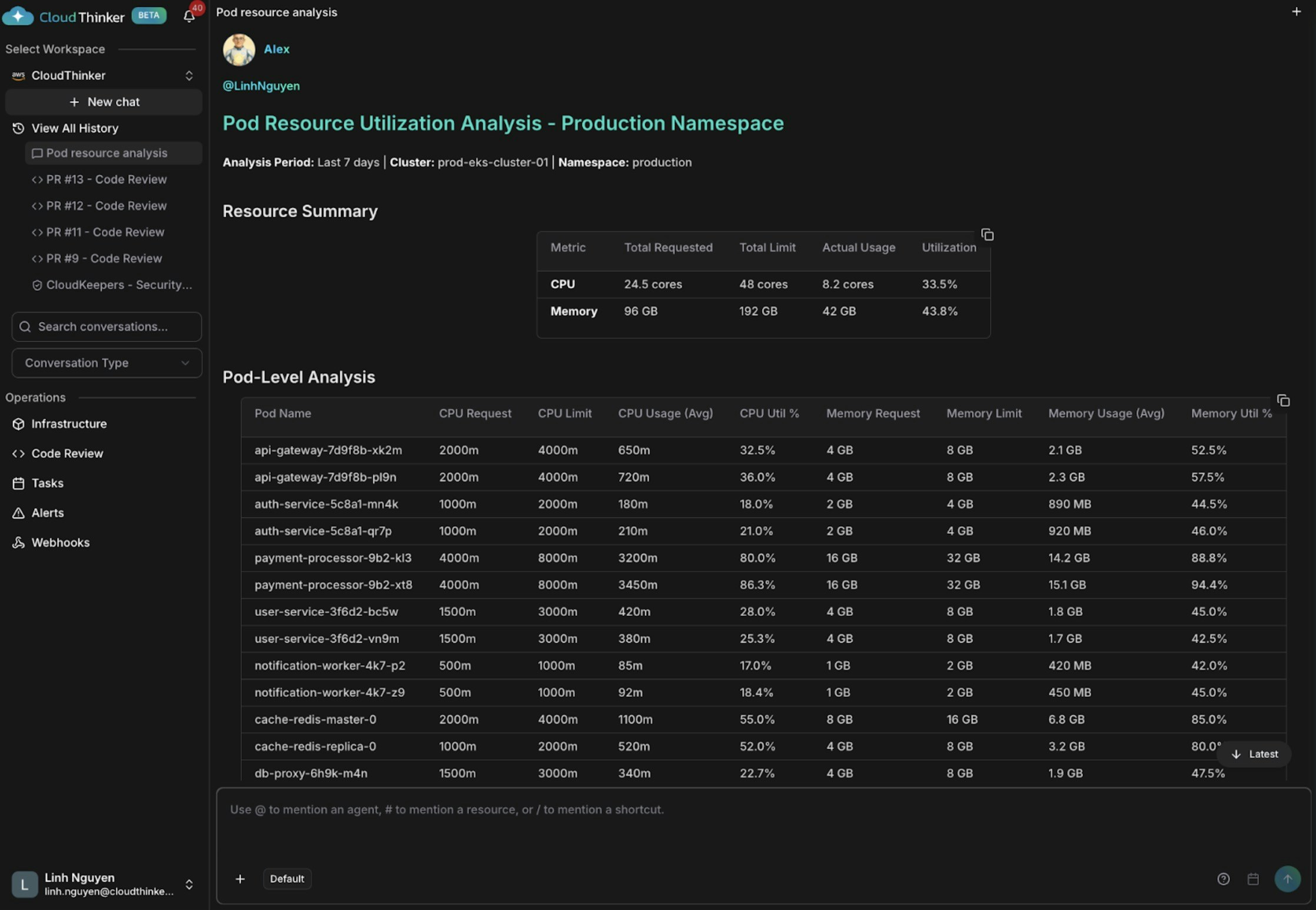
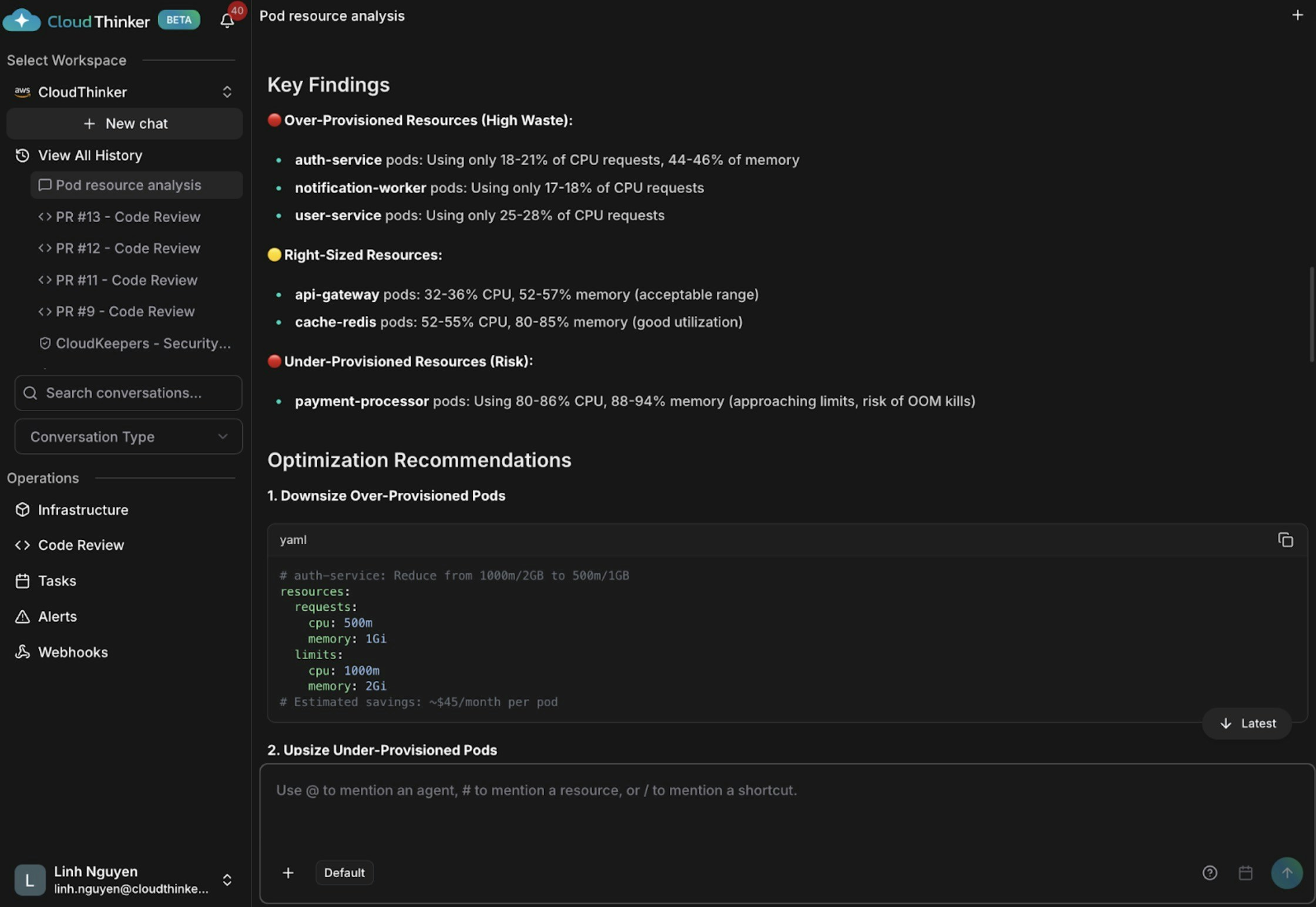
Kai は3つの知見を表面化します。auth-serviceとnotification-workerは過剰プロビジョニング(CPU使用率18〜21%)、api-gatewayとcache-redisは適切なサイズ、そしてpayment-processorはCPU 80〜86%・メモリ 88〜94%と危険なほど過小プロビジョニングされており、OOMキルとサービス障害の高リスク状態にあります。
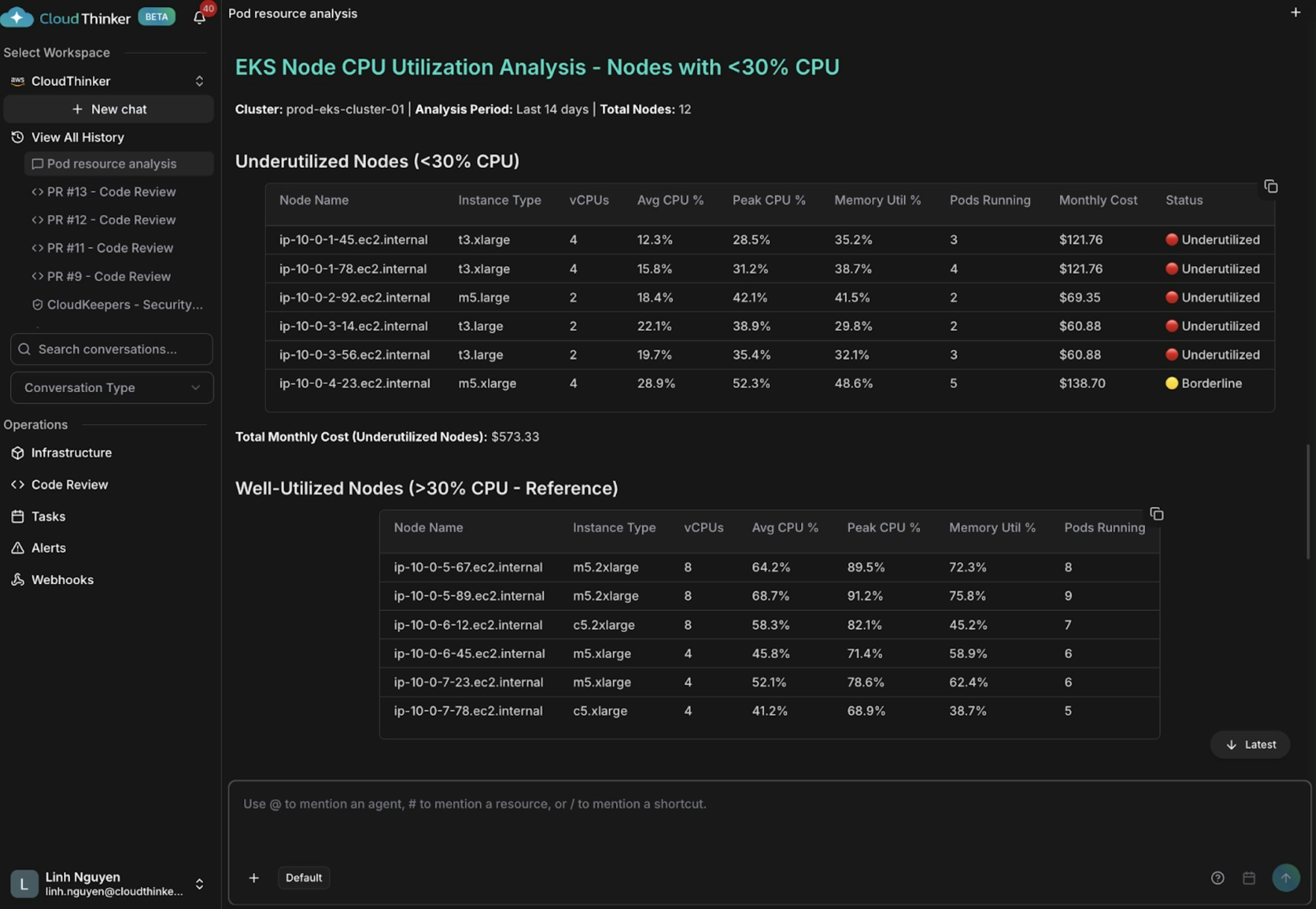
Kai は平均CPU使用率が30%未満(最低12〜15%のものもある)の5つのノードを発見し、月額約573ドルを無駄にしていることを特定します。軽量ワークロードで動作する過大サイズのt3.xlargeインスタンスと不適切なポッドスケジューリングの組み合わせにより、一部のノードにはポッドが2〜3個しかない一方、他のノードには8〜9個が集中しています。
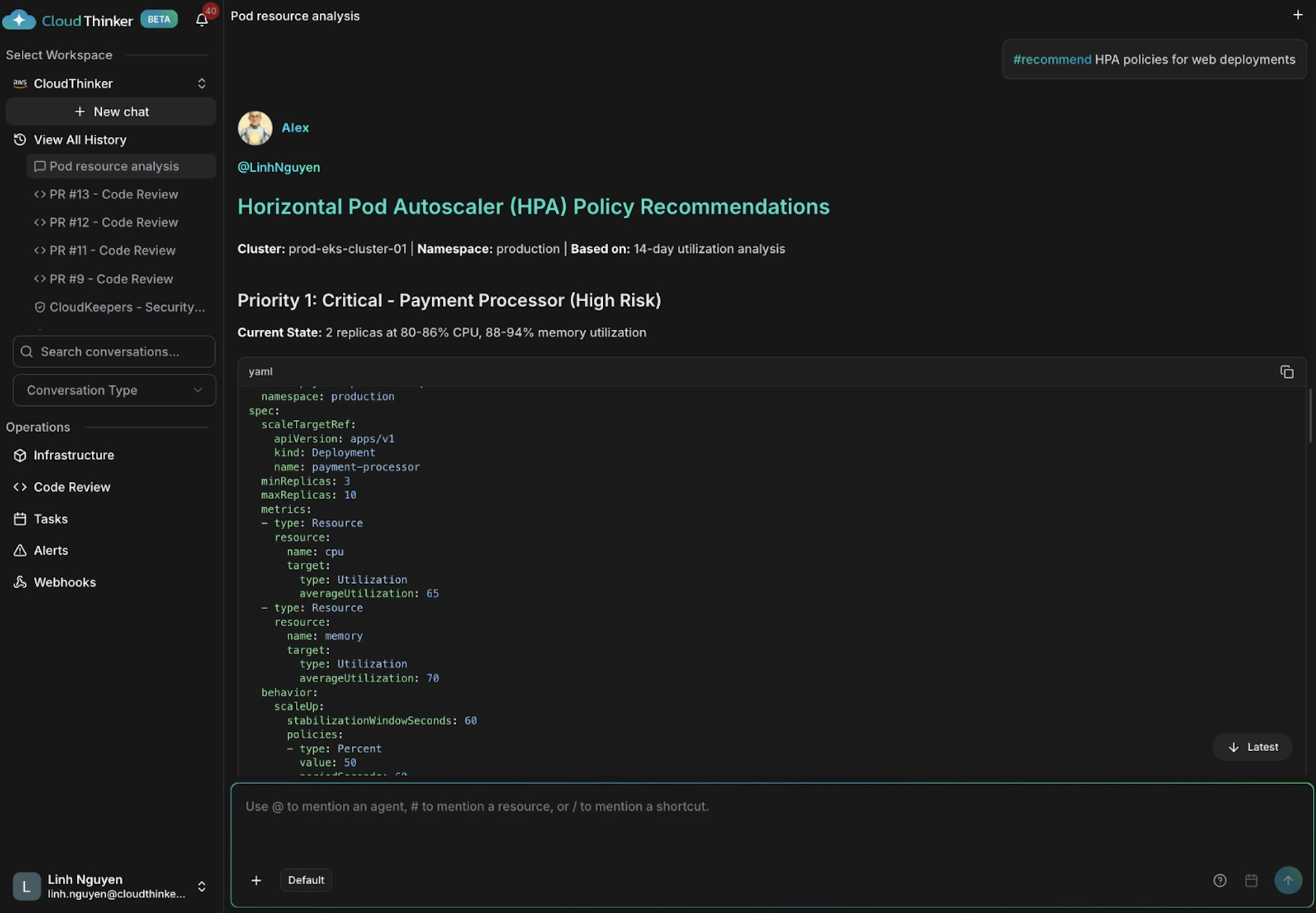
成果の要因
- Kai がクラスターAPIを直接クエリし、手動の
kubectlセッションとツール切り替えを置き換えます。 - クロスレイヤー相関により、ポッドの使用率・ノードキャパシティ・スケジューリングパターンを単一の分析パスでリンクします。
#reportと#chartが、Kai が知見を表面化する前に推論できる構造化された出力を生成します。#recommendが生のメトリクスダンプではなく、実行可能なHPAポリシー変更を生成します。- CloudKeepers がこの分析をスケジュール実行することで、オンコールエンジニアがページを受け取る前に知見が届きます。
試してみる
Kai エージェントリファレンス
KubernetesエンジニアエージェントKai の全機能
Kubernetes接続
CloudThinkerをEKSクラスターに接続するステップバイステップガイド
Topology Explorer
Kubernetesサービスの依存関係をマップし、インシデントの根本原因分析を迅速化
CloudKeepers
Kubernetesワークロード全体で継続的なヘルスチェックを自動実行